Go语言学习笔记(二)- 基础语法与数据类型
作为Java程序员,本章内容就走马观花的了解一下即可,这一章内容和其他语言没有太大的不同。
本章学习的内容
- 包申明、导入、main方法
- 变量声明(
var和:=的区别) - 基本类型:int、float、string、bool
- 常量与
iota - 类型转换
main方法
通过一个HelloWorld的程序,说明第一小节内容:包申明、导入包、main方法。创建一个main.go
1 | package main |
包申明:
1 | package main |
在Go语言中,每一个源文件都必须以package开头,它的作用就是定义了该文件属于哪个命名空间。这个名称可以随意定义,但main这个名称很特殊:
- 如果该文件的
package是main,那么这个程序将会被编译成一个可执行程序。 - 对于不同的文件,也可以将包名定义为
main,但是main方法只能有一个。
例如在main.go的同一级目录,创建一个utils.go,并且也声明为main。
1 | package main |
这样是可以的,但如果在这个文件里也定义一个main方法,作为项目整体运行的时候,就会报错。
错误: 软件包 hellogo 包含多个 main 函数
请考虑改用文件种类
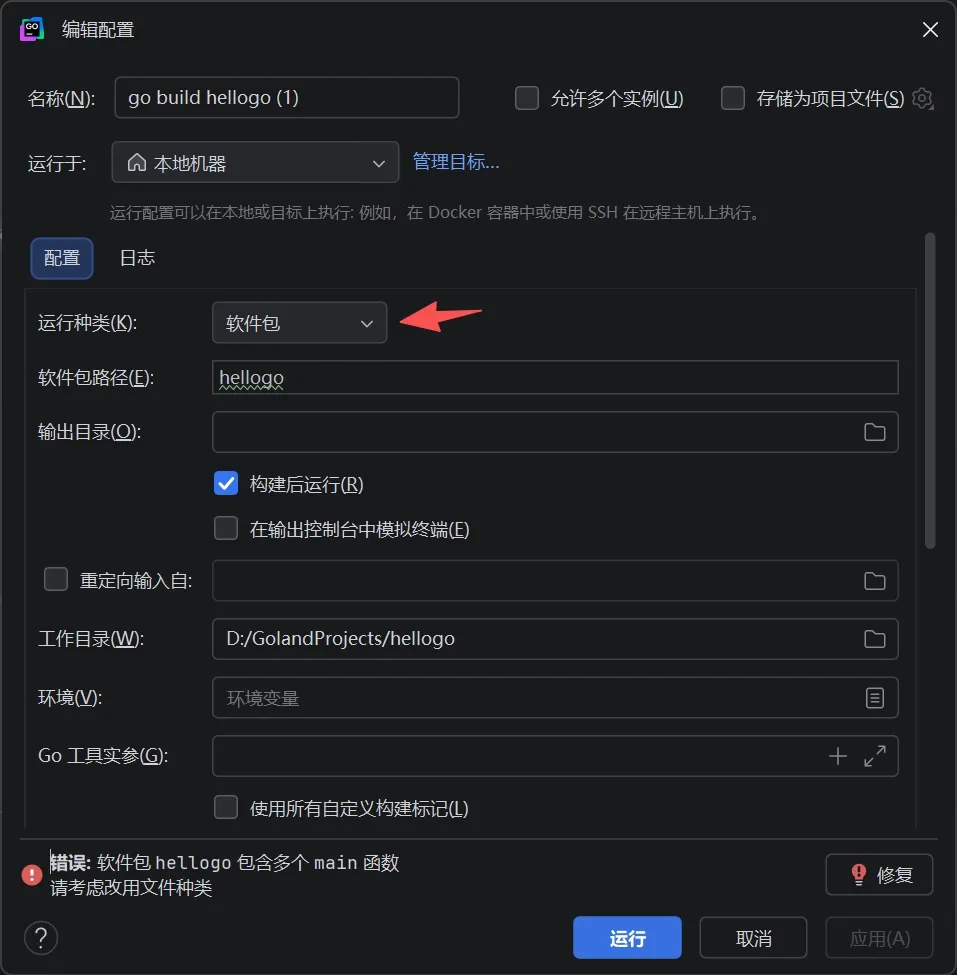
如果运行种类那里换成目录,会提示如下错误:
1 | # hellogo |
如果你在终端执行go run utils.go是可以执行的,因为它执行的模式是文件。

导入包:
1 | import "fmt" |
这就和Java差不多,主要的区别就是不用的包不允许导入。
包名必须使用双引号
”“包裹。导入的包必须使用,否则编译器会报错
如果有多个包,通常使用圆括号
1 | import ( |
main方法:
1 | func main() { |
和Java的public static void main(String[] args)一样,是程序的入口。
func关键字:用于定义方法(函数)- main方法不接受任何参数,也不返回任何值。
- 花括号必须跟在
main()后面, 如果使用c#那种换行会报错。
变量申明
在Go语言中,通常变量申明有两种方式:第一种是var,另一种是简洁的申明方式:=,二者略有区别。
单个变量申明
1 | package main |
和早期(JDK11以前)的Java不同,Go语言的类型时自己推断出来的,通常不需要显示的申明变量类型。
上述例子,分别体现了三种声明变量的方式:
- 类型推导:编译器根据等号右边的值自动判断
a1的类型是string,一旦确定,那么a1的类型就会固定,不能再修改为其他类型。 - 标准声明(var + 类型):会和Java一样,有一个默认值的机制:如果你只声明
var a int而不赋值,Go 会自动将其初始化为0(字符串是"",布尔是false)。 - 短变量申明
:=:偷懒专用,但只能使用在方法(函数)内部,不能用于包级变量,且必须至少有一个变量是新声明的。
批量变量申明:
1 | package main |
对于批量变量申明,只需要var(多个变量)即可,非常优雅。非常适合归类,对于同一类的变量可以申明到一起,还增加了可读性。
匿名变量
1 | package main |
如果某个方法返回的值不需要,为了避免代码报错,那么可以使用下划线_作为匿名变量,这也是比较常用的方式。
和导入包一样,未使用的变量也会报错,不用变量的请及时清理。(谁懂读别人Java代码的苦啊)
基本类型
Go语言的基本类型有:
整数类型
- 平台无关(需要明确长度的)
- 有符号:
int8、int16、int32、int64 - 无符号:
uint8、uint16、uint32、uint64 - 特殊别名:
byte:等用于uint8,常用于处理二进制原始数据。rune:等同于int32,专用用于表示一个Unicode字符(Java里的char?)
- 有符号:
- 平台相关
int/uint:在 32 位系统上占 4 字节,在 64 位系统上占 8 字节( Debian 13,int默认就是 64 位)。uintptr:无符号整数,大小足以存放一个指针的位模式,多用于底层unsafe编程。
在 Go 中,int 和 int64 被视为不同的类型。即使在 64 位系统上两者的长度相同,你也不能直接将 int 变量赋值给 int64,必须显式转换:int64(myInt)。
浮点型
float32:单精度浮点数(约7位有效数字)float64: 双精度浮点数(约15位有效数字),它是Go语言的类型推导的默认值。
所有语言的通病,也是面试题位数不懂相同的就是0.1 + 0.2的问题,Go也有!对于Java有BigDecimal,对于Go同样有shopspring/decimal。
字符串
字符串string(小写),它是不可变类型,一旦创建,字符串内部的字节序列就不允许修改。其次,它的默认编码是UTF-8,本质上上一个只读的字节切片([]byte)。
有几个坑需要注意:
len()返回的是字符串的字节长度,而非字符个数
1 | s := "Hello Go语言" |
当然,非要统计字符个数,请使用unicode/utf8这个包
1 | import ( |
布尔类型
类型名为bool,默认值为false,取值只有两个:true或者false,不允许像c那样,将0当作false。
常量与iota
常量
Go语言的常量使用const定义,可以显式声明类型,也可以利用类型推导。和其他语言一样,编译时就确定了值,并且不可改变。
其规则如下:
- 编译时确定:常量的赋值必须是一个在编译期就能确定的值(如字面量、算术运算、内置函数如
len())。不能把一个函数的返回值赋值给常量。 - 批量申明
- 常量展开(跳过赋值):在一组常量中,如果某一行没有写赋值,那么它会自动复用上一行的表达式。
下面通过一个例子来说明
1 | //常量 |
iota(常量计数器)
iota 是 Go 语言的一个特殊常量,它被设计用来简化累加数字的定义。你可以把它理解为 const 块中的行索引。通常用来做枚举、错误码、权限位、物理单位、状态机等。
iota 的基本行为
iota在const关键字出现时将被重置为 0。- 每新增一行常量声明,
iota就会自动累加 1。
1 | // 这里还使用了常量展开,学以致用。 |
如果像跳过某个值,可以使用如下方式:
1 | const ( |
iota 最强大的地方在于它不仅能代表数字,还能参与位运算。这在定义权限、状态位或文件单位时非常高效。
1 | const ( |
还有存储单位:
1 | const ( |
对于整形和浮点型,还有一个类型的问题:
- 无类型常量:
const x = 123,它们具有“高精度”且没有固定类型,可以根据上下文自动转换。 - 类型化常量:如
const x int32 = 123。它的类型是死板的,只能与int32运算。
类型转换
Go 语言的类型转换遵循一个核心原则:显式大于隐式。它不支持像Java那样的括号强转(int) a,并且只有两种类型相互兼容时,才能转换(数值类型、或者对象底层结构相同)。
语法T(v)
Go 的类型转换非常直观,语法类似于函数调用:将变量 v 转换为类型 T。
1 | // 直接用testing了,省得互相干扰 |
数值转换时,开发者必须亲自处理溢出和精度丢失的问题。
从浮点数转为整数时,小数部分会被直接截断,而不是四舍五入。
1 | f := 3.9889 |
如果将大范围类型转换为小范围类型时,会发生截断。
1 | var d int64 = 257 |
还有一个比较常见的场景,那就是字符串与切片的转换:
字符串与字节切片([]byte)
Go 的字符串底层就是字节数组,转换效率很高,但会发生内存拷贝(除非使用 unsafe 包)。
1 | func Test_StringCovert(t *testing.T) { |
字符串与字符切片([]rune)
如果需要按字符(Unicode)处理中文,必须转为 []rune。
1 | func Test_StringCovert(t *testing.T) { |
字符串与数值的转换
从这里开始,之前的语法T(v)就不好使了。需要使用strconv这个包
1 | package main |
看样子除了string<->int,其他的都是ParseT和FormatT,并且使用ParseT的时候,会返回多返回err,学习阶段使用匿名变量接收即可,实际开发中需要判断错误。
 wechat
wechat alipay
alipay