1. 前言
通常我一直在虚拟机中安装Hadoop、Hive、Hbase等大数据相关的组件,但随着我的笔记本使用年限越爱越长,性能也下降的很快,已经达到开虚拟机就会开的地步,于是我就考虑直接将Hadoop安装到macOS上,避免了虚拟机对资源的消耗,为了更好的管理,我选择使用brew来安装。
2. 安装Hadoop
使用brew安装Hadoop非常方便,执行如下命令即可:
brew install hadoop安装前建议提前安装好JDK,并且配置JAVA_HOME。
为了方便使用,我还配置了hosts
sudo vim /etc/hosts
127.0.0.1 hadoop3. 配置Hadoop
3.1. 配置免密登录
macOS默认是关闭了远程登入的功能,所以需要先打开它。打开系统偏好设置 -> 共享,左边勾选远程登录,右边选择仅这些用户,并且把当前用户添加进去。
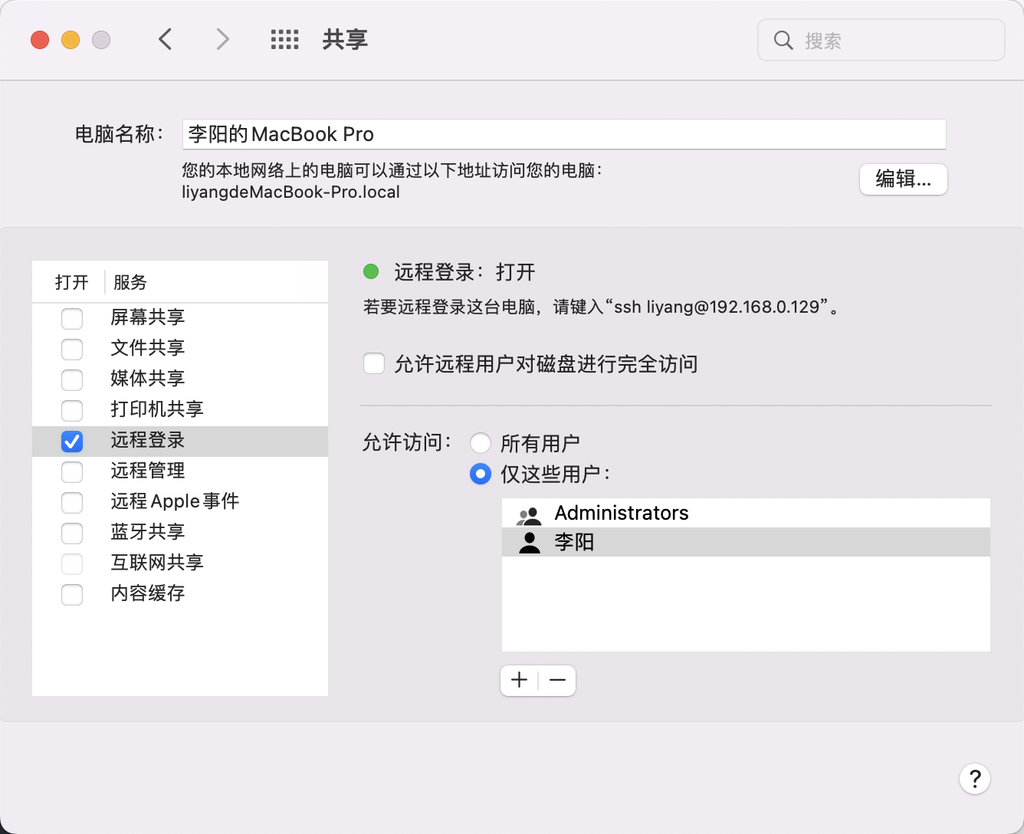
然后生成秘钥和公钥
# 生成公钥和私钥
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
# 将公钥追加到authorized_keys,实现免密登录
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
# 修改相关权限,避免不生效
chmod 0600 ~/.ssh/authorized_keys
# 配置完成后ssh localhost测试,是否需要密码。
ssh hadoop3.2. 修改Hadoop配置文件
brew安装在/usr/local/Cellar/hadoop/3.3.4。
修改hadoop-env.sh
vim /usr/local/Cellar/hadoop/3.3.4/libexec/etc/hadoop/hadoop-env.sh
# 配置JAVA_HOME
export JAVA_HOME=/Library/Java/JavaVirtualMachines/jdk-11.0.17.jdk/Contents/Home修改core-site.xml
vim /usr/local/Cellar/hadoop/3.3.4/libexec/etc/hadoop/core-site.xml填入如下内容:
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://hadoop:8020</value>
</property>
<!-- 以下配置可防止系统重启导致NameNode 不能启动-->
<!-- /Users/用户名/data 这个路径你可以随便配置, hadoop必须有权限-->
<property>
<name>hadoop.tmp.dir</name>
<value>/Users/liyang/Documents/hadoop/tmp</value>
<description>A base for other temporary directories.</description>
</property>
<!-- DataNode存放块数据的本地文件系统路径 -->
<property>
<name>dfs.name.dir</name>
<value>/Users/liyang/Documents/hadoop/filesystem/name</value>
<description>Determines where on the local filesystem the DFS name node should store the name table. If this is a comma-delimited list of directories then the name table is replicated in all of the directories, for redundancy. </description>
</property>
<property>
<name>dfs.data.dir</name>
<value>/Users/liyang/Documents/hadoop/filesystem/data</value>
<description>Determines where on the local filesystem an DFS data node should store its blocks. If this is a comma-delimited list of directories, then data will be stored in all named directories, typically on different devices. Directories that do not exist are ignored.</description>
</property>
</configuration>修改hdfs-site.xml
vim /usr/local/Cellar/hadoop/3.3.4/libexec/etc/hadoop/hdfs-site.xml填入如下内容:
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop:9868</value>
</property>
<property>
<name>dfs.namenode.http-address</name>
<value>hadoop:9870</value>
</property>
<property>
<name>dfs.namenode.rpc-address</name>
<value>hadoop:8020</value>
</property>
</configuration>修改mapred-site.xml
vim /usr/local/Cellar/hadoop/3.3.4/libexec/etc/hadoop/mapred-site.xml填写如下内容:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>修改yarn-site.xml
vim /usr/local/Cellar/hadoop/3.3.4/libexec/etc/hadoop/yarn-site.xml填写如下内容:
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
</configuration>修改workers
vim /usr/local/Cellar/hadoop/3.3.4/libexec/etc/hadoop/workers
# 默认内容是localhost,可以不改,因为我设置了别的host,所以我需要修改一下
hadoop3.3. 创建目录
mkdir -p /Users/liyang/Documents/hadoop4. 启动Hadoop
4.1. 设置环境变量
vim ~/.zshrc
export HADOOP_HOME="/usr/local/Cellar/hadoop/3.3.4/libexec"
export PATH="$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin"
export HADOOP_CONF_DIR="/usr/local/Cellar/hadoop/3.3.4/libexec/etc/hadoop"4.2. 格式化HDFS
hdfs namenode -format4.3. 启动所有服务
# 如果start-all提示不存在的命令,那可能是你环境变量没配置,或者配置了没生效。
start-all会输出如下:
(base) ➜ ~ start-all.sh
WARNING: Attempting to start all Apache Hadoop daemons as liyang in 10 seconds.
WARNING: This is not a recommended production deployment configuration.
WARNING: Use CTRL-C to abort.
Starting namenodes on [hadoop]
Starting datanodes
Starting secondary namenodes [hadoop]
2023-06-20 21:00:36,813 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Starting resourcemanager
Starting nodemanagers
# 查看进程
(base) ➜ ~ jps
14914 NameNode
10739
15526 Jps
15160 SecondaryNameNode
15354 ResourceManager
15018 DataNode
15454 NodeManager访问 web address查看状态
- NameNode: http://localhost:9870
- ResourceManager: http://localhost:8088/cluster
- NodeManager: http://localhost:8042/node
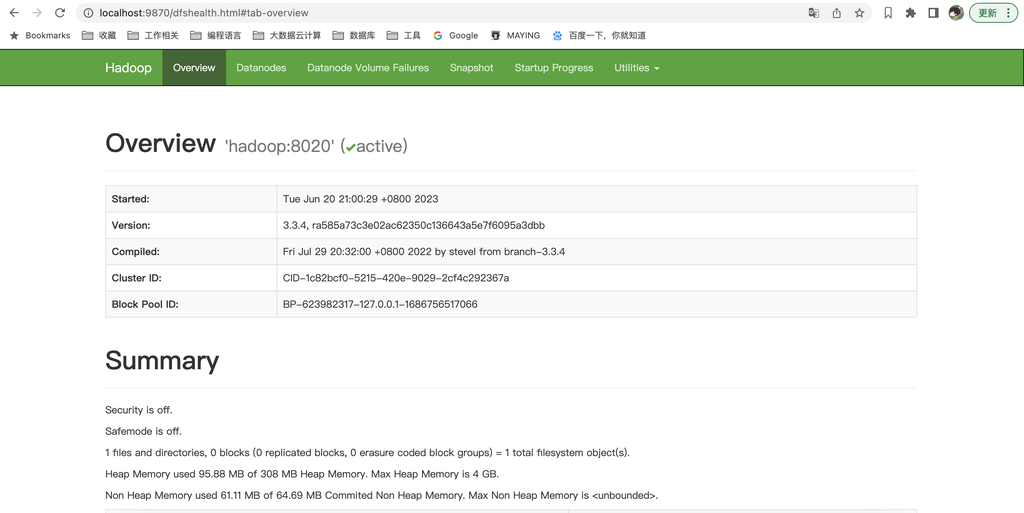
执行命令测试是否正常
(base) ➜ ~ hadoop fs -ls /
2023-06-20 21:06:47,933 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
(base) ➜ ~ hadoop fs -mkdir /test
2023-06-20 21:06:56,633 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
(base) ➜ ~ hadoop fs -ls /
2023-06-20 21:07:01,184 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Found 1 items
drwxr-xr-x - liyang supergroup 0 2023-06-20 21:06 /test这里会输出大量的WARN,表示没有加载本地库,这个解决办法可参考如下:
https://www.cnblogs.com/shoufeng/p/14940245.html
我选择了修改日志,本来只是为了学习使用,没必要追求这些性能。













