第一次接触Prometheus还是2018年参加QCON北京会议时听的一场Prometheus的讲座,当时所在的公司监控系统主要使用的zabbix,应用级的监控使用的是Pinpoint的二次开发,所以对于Prometheus的了解还只是听闻,尽管很想使用,但是公司的zabbix已经非常成熟,包括后来小米的open-falcon也是没有机会去使用。直到今天我才想着要不测试环境的服务都用Prometheus吧,因现在的公司并没有监控系统,服务挂了以后都是使用的时候才会发现。我个人是比较喜欢docker的,于是有了此篇文章。
角色分配
- Prometheus 采集数据
- Grafana 用于图表展示
- redis_exporter 用于收集redis的metrics
- node-exporter 用于收集操作系统和硬件信息的metrics
- cadvisor 用于收集docker的相关metrics
安装Docker
我通常使用如下命令安装最新版的docker
wget -O /etc/yum.repos.d/docker-ce.repo https://download.docker.com/linux/centos/docker-ce.repo && yum install -y docker-ce && systemctl enable docker.service && service docker start
安装Docker-Compose
可以使用如下命令安装最新版的docker-compose
curl -L https://github.com/docker/compose/releases/download/1.24.1/docker-compose-`uname -s`-`uname -m` -o /usr/local/bin/docker-compose chmod +x /usr/local/bin/docker-compose
在安装过程中下载时间需要40分钟,仅仅15M的东西,所以可以通过如下方式手动下载:
echo "https://github.com/docker/compose/releases/download/1.24.1/docker-compose-`uname -s`-`uname -m`"
输出如下:
https://github.com/docker/compose/releases/download/1.24.1/docker-compose-Linux-x86_64
点击下载,完成后上传到服务器上,然后执行如下命令:
mv docker-compose-Linux-x86_64 /usr/local/bin/docker-compose chmod +x /usr/local/bin/docker-compose
部署Prometheus和Grafana
新增Prometheus配置文件
首先,创建/data/prometheus/目录,然后创建prometheus.yml,填入如下内容:
global:
scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.
# scrape_timeout is set to the global default (10s).
# Alertmanager configuration
alerting:
alertmanagers:
- static_configs:
- targets: ['10.10.170.161:9093']
# - alertmanager:9093
# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files:
- "node_down.yml"
# - "first_rules.yml"
# - "second_rules.yml"
# A scrape configuration containing exactly one endpoint to scrape:
# Here it's Prometheus itself.
scrape_configs:
# The job name is added as a label `job=` to any timeseries scraped from this config.
- job_name: 'prometheus'
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
static_configs:
- targets: ['10.10.170.161:9090']
- job_name: 'redis'
static_configs:
- targets: ['10.10.170.161:9121']
labels:
instance: redis
- job_name: 'node'
scrape_interval: 8s
static_configs:
- targets: ['10.10.170.161:9100']
labels:
instance: node
- job_name: 'cadvisor'
static_configs:
- targets: ['10.10.170.161:8088']
labels:
instance: cadvisor
接着创建node_down.yml,添加如下内容:
groups:
- name: node_down
rules:
- alert: InstanceDown
expr: up == 0
for: 1m
labels:
user: test
annotations:
summary: "Instance {{ $labels.instance }} down"
description: "{{ $labels.instance }} of job {{ $labels.job }} has been down for more than 1 minutes."
创建docker-compose
继续在/data/prometheus/目录中创建docker-compose-prometheus.yml,添加如下内容:
version: '2'
networks:
monitor:
driver: bridge
services:
prometheus:
image: prom/prometheus
container_name: prometheus
hostname: prometheus
restart: always
volumes:
- /data/prometheus/prometheus.yml:/etc/prometheus/prometheus.yml
- /data/prometheus/node_down.yml:/etc/prometheus/node_down.yml
ports:
- "9090:9090"
networks:
- monitor
grafana:
image: grafana/grafana
container_name: grafana
hostname: grafana
restart: always
ports:
- "3000:3000"
networks:
- monitor
redis-exporter:
image: oliver006/redis_exporter
container_name: redis_exporter
hostname: redis_exporter
restart: always
ports:
- "9121:9121"
networks:
- monitor
command:
- '--redis.addr=redis://10.10.170.161:7000'
node-exporter:
image: quay.io/prometheus/node-exporter
container_name: node-exporter
hostname: node-exporter
restart: always
ports:
- "9100:9100"
networks:
- monitor
cadvisor:
image: google/cadvisor:latest
container_name: cadvisor
hostname: cadvisor
restart: always
volumes:
- /:/rootfs:ro
- /var/run:/var/run:rw
- /sys:/sys:ro
- /var/lib/docker/:/var/lib/docker:ro
ports:
- "8088:8080"
networks:
- monitor
这里的端口号已经redis-addr请修改成自己的。
启动docker-compose
使用下面的命令启动docker-compose定义的容器
docker-compose -f /data/prometheus/docker-compose-prometheus.yml up -d
输出如下内容即代表启动成功:
Creating network "prometheus_monitor" with driver "bridge" Creating cadvisor ... done Creating prometheus ... done Creating node-exporter ... done Creating redis_exporter ... done Creating grafana ... done
也可通过docker ps命令查看是否启动成功。如果要关闭并删除以上5个容器,只需要执行如下命令即可:
docker-compose -f /data/prometheus/docker-compose-monitor.yml down
同样也会输出如下日志:
Stopping cadvisor ... done Stopping node-exporter ... done Stopping grafana ... done Stopping redis_exporter ... done Stopping prometheus ... done Removing cadvisor ... done Removing node-exporter ... done Removing grafana ... done Removing redis_exporter ... done Removing prometheus ... done Removing network prometheus_monitor
打开http://10.10.170.161:9090/targets,如果State都是UP即代表Prometheus工作正常,如下图所示:
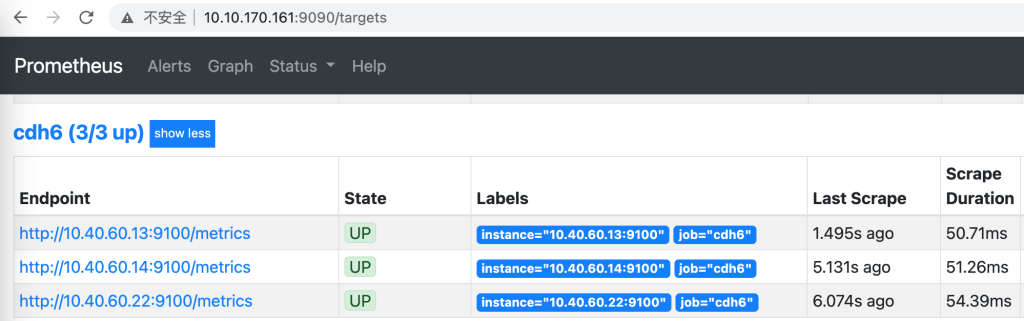
如果只有一个UP,可以检测下防火墙的问题
firewall-cmd --zone=public --add-port=9100/tcp --permanent firewall-cmd --zone=public --add-port=8088/tcp --permanent firewall-cmd --zone=public --add-port=9121/tcp --permanent firewall-cmd --zone=public --add-port=3000/tcp --permanent firewall-cmd --zone=public --add-port=9090/tcp --permanent firewall-cmd --reload
可通过如下命令查看端口策略是否已经生效
firewall-cmd --permanent --zone=public --list-ports
配置Grafana
打开http://10.10.170.161:3000,使用默认账号密码admin/admin登录并修改密码后,默认进来是创建数据库的页面,在如下图所示中,选择Prometheus。
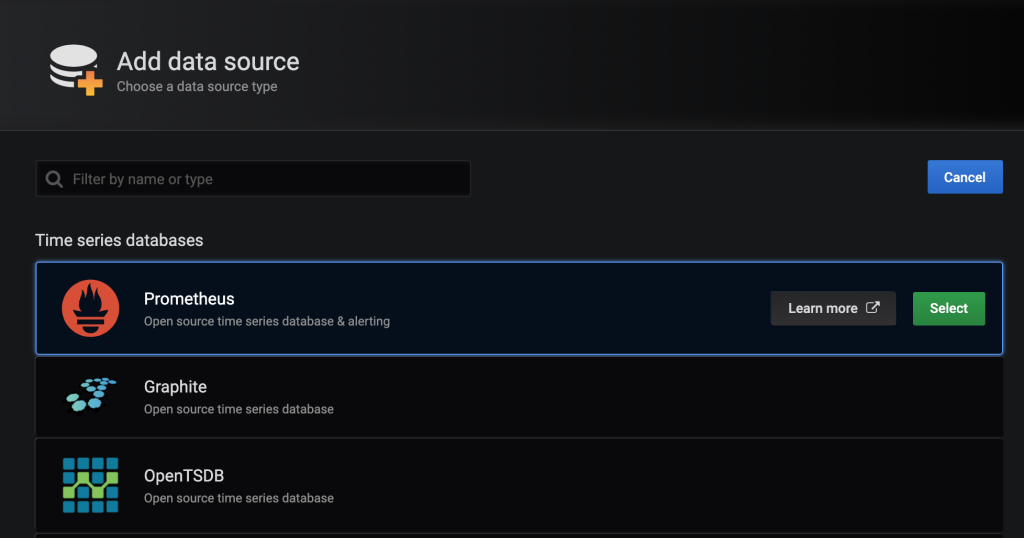
选择完成后,打开新的页面,在HTTP的URL中输入Prometheus的地址http://10.10.170.161:9090,并且将Access由Server更换为Browser,因为跨域的问题Server无法使用。点击保存并测试。

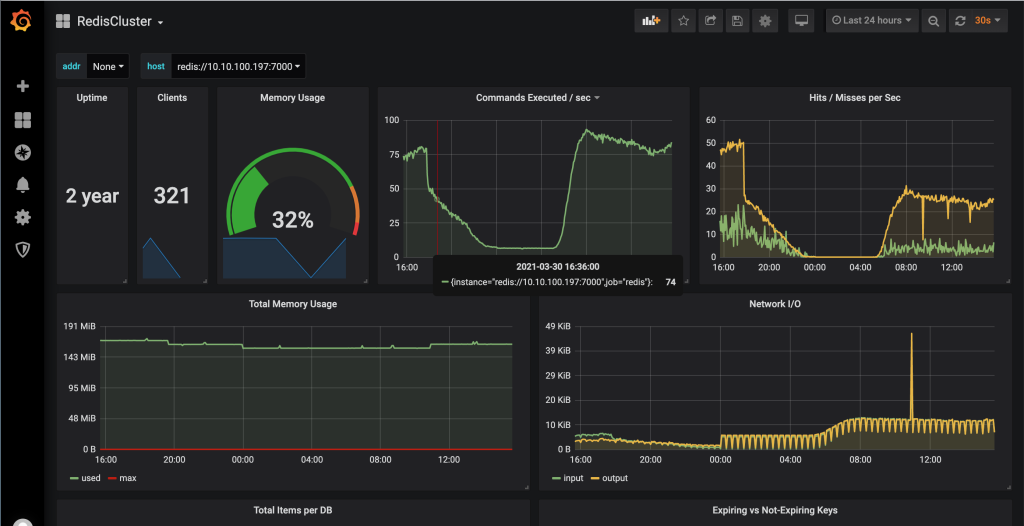
现在数据源已经接通了,只剩下漂亮的报表了,在https://grafana.com/grafana/dashboards中搜索需要的Dashboard模版,并将其json文件下载下来。我本次主要监控docker与redis,于是只需要下载下面两个即可:
在Grafana菜单栏中第一个+号中,选择import
将其上传后,选择prom为Prometheus也就是配置Prometheus是的Name的值,点击保存即可。等待一会儿就会出现如下界面: